1 - Contribute to Vixen
How to contribute to the Vixen application.
Overview
Vixen is an open source project and we appreciate getting patches and contributions to make Vixen and its documentation even better.
The Vixen application code is hosted on Github. You can clone the repository to get a copy of the source code to work with.
Development Libraries
There are a few libraries and tools that you need to have installed in order to get the application to build. Depending on how much you develop in other projects you may have these already installed.
- Windows 10 or higher.
- Visual Studio 2022 / Visual Studio Code with appropriate plugins.
- MSVC v143 VS 2022 C++ tools / C++ build tools for Visual Studio Code.
- Git >= 2.47
- Microsoft .NET 8
- Microsoft Visual C++ x64 Redistributable
Project libraries are included in the source tree, or included via Nuget. Familiarity with Nuget is necessary.
The current build target is .NET 8 Windows and Visual C++. We no longer maintain x86 builds.
See this article on Visual Studio settings you should use.
See this article for information on Git.
Workflow
When contributing to Vixen, we track all issues and improvements in our JIRA bug tracker. Work should have an associated issue created for it. It will be necessary to have an account in JIRA so you can work with the issues. See Lifecycle of an issue for guidance on how we manage issues. When you become a contributor, we can add you to the appropriate access groups to facilite workign with the issues beyond a simple user.
You should name your branches with the JIRA issue number. i.e. VIX-2345. Any commits to the branch should start with the same issue number as well. From there follow Git guidelines for commit messages. All commit messages should strive to be useful to provide context of the change. All submissions are done through pull requests on Github. See Branching Practices for guidance on this topic.
Commit messages should be descriptive and helpful for those who do not know what you changed. Each commit message titel should start with the JIRA issue id. Beyond that, you should follow Github guildlines for formatting your commit messages. Git Commit Message.
Commit message example.
VIX-1234 Fixing the invalid dialog message
- Add the correct dialog message showing the error that happened.
- Removed the info icon and replaced it with the error icon.
More information on how we manage JIRA can be found here. Issue Management.
Project Structure
Vixen 3 is a modular application that allows for pluggable modules to be developed for it. It is written in C# and some small parts in C++. The UI consists of a mix of Winforms and WPF. The WPF sections generally follow the MVVM pattern with most of it using CATEL for the MVVM library. Any new UI should favor WPF where appropriate. The code structure is as follows under the src folder:
- /Vixen.Common - Common components used by the application and modules
- /Vixen.Modules - Modules developed and maintained by the core team, and other contributors
- /Vixen.Application - The main Vixen application
- /Vixen.Core - The Vixen core framework
- /Vixen.Installer - Installer projects
Conventions for development:
-
The assembly name should be the name of the module (eg. TimedSequenceEditor), and
-
the default namespace should be “Module.ModuleType.ModuleName”. For
example, Modules.Editor.TimedSequenceEditor.
-
The build output directory should be relative to the solution directory, in a
‘Release’ directory release builds and a Debug folder for Debug builds. We no longer actively support x86 builds.
It will also depend on the type of module. For example:
Vixen Modules (Release): $(SolutionDir)\Release\Output\Module.ModuleType.ModuleName
Vixen Common assemblies (Release): $(SolutionDir)\Release\Output
Vixen Applications (Release): $(SolutionDir)\Release\Output\
-
Assembly names are handled by the Directory.Build.Props file for each module type.
-
To reference the Vixen project (or any other projects that are needed), make sure you
add a ‘project reference’, and not a “normal” reference (to the binary DLL). This will help compatibility for other developers when used in different locations. References to projects should be set so they do not copy local. This avoids assembly loader issues with multiple copies. Under Properties of the reference.
- Copy Local : No
- Include Assets: None
-
NuGet packages follow the same principle as Project References. You should include the package in the Common area and allow the libraries to be deployed in that path. Then in the local project the NuGet package is added but is set not to copy the assets locally by setting the following in the properties of the library.
Developer Group
We maintain a developer group for broader discussions on Google Groups. If you are looking to join us as a contributor, please join the Vixen Development Group and introduce yourself and decscribe your interests in contributing. We can help you get started. See the Communty Page for more information on how to connect.
Creating Issues
Alternatively, if there’s something you’d like to see in Vixen (or if you’ve found something that isn’t working the way you’d expect), but you’re not sure how to fix it yourself, please create an Issue in our JIRA board for anything in the application.
3 - Git Information
This section covers the source code tooling.
Overview
The Vixen project uses Git for our source code management. Github is our collaboration tool.
There are many tools to work with a Git based project. You will at minimum need the Git libraries installed.
Git SCM
Github SSH integration
In order to use Github and interact with it on the command line you need to ensure you have the proper SSH keys configured. See the following article on how to configure SSH access.
Connect to Github via SSH
TortoiseGit
TortoiseGit is a UI tool that can make it easier for some to use Git. This allows you to make commits, view history, etc. without having to use the command line tools in Git itself. It is popular in the SVN world, so there may be some familiarity from there if you come from the SVN space.
TortoiseGit Manuals
GIT Bash Integration
Here’s a project to add the branch info to the prompt in Git Bash. This is similar to the Powershell one but has some slight variations. There are likley many other variations out there that you can try out to find what suits you the best.
Git Bash Prompt
Git Powershell Integration
posh-git is a PowerShell module that integrates Git and PowerShell by providing Git status summary information that
can be displayed in the PowerShell prompt, e.g.:
![C:\\Users\\Keith\\GitHub\\posh-git [main ≡ +0 ~1 -0 | +0 ~1 -0 !]>](https://github.com/dahlbyk/posh-git/wiki/images/PromptDefaultLong.png "~\\GitHub\\posh-git [main ≡ +0 ~1 -0 | +0 ~1 -0 !]>")
posh-git also provides tab completion support for common git commands, branch names, paths and more.
For example, with posh-git, PowerShell can tab complete git commands like checkout by typing git ch and pressing
the tab key. That will tab complete to git checkout and if you keep pressing tab, it will
cycle through other command matches such as cherry and cherry-pick. You can also tab complete remote names and
branch names e.g.: git pull or<tab> ma<tab> tab completes to git pull origin main.
See the Install Docs for details on how to install it into your Powershell profile.
Visual Studio
Visual Studio also has support within it for Git and there are also many other plugins that provide integrations as well. You can also utilize a Powershell terminal into one of the docking panes and then the command line tools are readily available. Using posh-git mentioned above enhances this experience.
Branching Practices
The general idea is that the master branch is, tracking the development for the next version. It’s stuff that’s going into the product, and will be included in the next version unless something is found to have an issue in testing.
-
You should not commit code to your master branch. You should keep it up to date with the real master and make branches off of it for any new work you do. When you first decide to do work on Vixen, you should fork the master at Github to your own copy of it. You should be able to build and get a running version of Vixen from that is current. Then you can easily make branches from that to work on.
-
All work should be done based off of a ticket in the Bug Tracker. When you take on work for a particular item, you should create a branch off of the current master and name it the same as the ticket you are working on. I.E. VIX-1024. This provides a clear reference back to the description of the problem or feature. In addition to this, each commit should start with the ticket number. This will allow those commits to be linked to the ticket when they are eventually merged into the master. You should ensure you have an open ticket to begin work so that this tracking can occur. Once the ticket it open and assigend to you, you can move it to start work. This will indicate to other developers you are working on the ticket. Once you complete the work, you can submit a pull request to the Vixen repository where it can be reviewed. The JIRA ticket will reflect that a pull request has been submitted. Once reviewed and approved, the ticket will transition states based on it being merged, built and closed automatically. You will not need to transition JIRA beyond the initial start work in normal circumstances. The build that corresponds to the change will be marked in the JIRA ticket along with links to the commits involved. The maintainer will close the ticket when it is merged.
-
If the item you are working on will span some time and the current master gets updated with new features from other developers, you can keep your branch in sync by rebasing your changes onto the current version of the master. You would do a git pull to your master from the master branch tree first. Then you can rebase your branch onto that. This will replay your commits onto the tail of the master giving you a up to date branch. Try to avoid merging the changes in the master into your own branch as this creates a messy commit history. More information on how to rebase can be found here.
-
If you are collaborating with another developer, then you may want to share work on a branch. Here you can both work on the same branch shared publicly or you can merge changes between yourself. This is not very common in our development structure, so ask questions if it comes up and we can help guide you through it.
-
Larger bodies of work will be conducted on a feature branch in the repository. Here something like an Epic can we worked on by multiple developers, or broken up into multiple parts and that can be assembled on the feature branch and then a singular pull request can merge the entirety of that back to master.
Rebase vs Merge
In this project we prefer developers rebase their changes onto the latest master when there are conflicts. Rebase provides for a cleaner inline history in our opinion. Not all changes require a rebase / merge to update before presenting a PR, but in many cases is can be beneficial to test your work completely integrated with the mainline. There are benefits when you are working on changes that may span enough time that multiple other changes are incorporated into the mainline. Incremental rebasing can help keep you up to date and allow you to resolve smaller incremental conflicts as you go along.
Git Rebase
4 - Issue Management
This section covers managing issues in JIRA.
Overview
We use JIRA to track feature requests, bug reports, improvements, and other development-related work for the Vixen application. This page will explain the structure and layout of some of the JIRA tickets, the processes we go through when working on them, and any other related notes. For documentation issues, see Contributing to Documentation.
The JIRA bug tracker can be found here. We are currently utilizing the cloud version of JIRA, so the link here will redirect you to the Atlassian location for our cloud instance. If you have a question that is not answered on this page, please ask!
The purpose of JIRA is to keep track of any outstanding issues relating to Vixen. These might be bugs with existing functionality, or requests for new features (or improvements to existing ones). Please try and make sure that we track ALL work that needs to be done in JIRA, as it lets us keep a record of it. So often there is a bug report posted on the DIYC forum, or the Dev mailing list, which goes unanswered (or unsolved), and gets forgotten. Please try and make new tickets for everything; they’re easy to close if needed!
JIRA Tickets
JIRA tickets have a number of fields that can be used to help describe and categorize an issue. Some are mandatory, some are useful, and some not as much. When creating a ticket, ensure you complete the items in the following list with an asterisk (*).
- Issue Type (*) Can be one of five values:
- Epic To track larger projects that are underway. Do not use.
- Bug Something in the software does not work as described or expected.
- Improvement An existing feature could be improved with this work.
- New Feature This does not exist in the software, and would improve it.
- Task Used to track miscellaneous development work, not strictly tied to the software functionality (eg. code cleanup, research, etc.)
- Summary (*) One-line title of the issue.
- Priority: Defaults to Major, not often changed. Can change if it’s particularly important or not.
- Component/s (*) One or more areas of the software that this relates to. Ask for new ones if needed.
- Affects Version Only used when reporting a bug.
- Fix Version This should be added when the code is merged and will be included in the next version.
- Assignee/Reporter Who is working on it, and who reported it.
- Description/Attachements (*) Include as much detail about the problem here. If needed, attach config files, sequences, logs, etc.
- Task Group We tried to use this to track a rough timeframe of when work would be done. Finding it too hard to predict, so we’ve stopped using it.
- Epic Link Which Project of work this falls under, if any. Leave empty unless you’re sure of what it should be.
Epic/Project Tickets
The Epic tickets are used to track large chunks of work, as there may be a number of bugs or requested improvements related to one particular field. For example, there’s many improvements to the sequencer to be considered when we revamp the sequencer, so these are all grouped together to make it easy to track them, review them, etc.
We have a number of Epics are the moment. Some are just to collate small related problems, and others are to section out large chunks of work that have many facets that need considering. These should help to make it easier to track work on a single Topic. Since we often get developers that are interested in one particular area, this will make it easier to point them at a single point to manage the work being done.
Lifecycle of a Ticket
The lifecycle of a Vixen ticket can be seen below. A full explanation of the process follows.
Note that to be able to do a some of these functions, you need to have appropriate permissions. Most active developers will need the JIRA Developer role. If you are unable to take tickets or progress them through the workflow, ask the dev group, and we can change your permissions.
- A ticket is created (eg. a user reports a bug, requests a feature, or a developer makes a ticket for work they have been doing). It may be assigned to someone specific if relevant.
- Someone takes it, and starts working on it (even if it’s just reviewing it, or reproducing the issue). They assign it to themselves, and change it to In Progress. This helps prevent multiple people duplicating work. If you are doing work on a Git branch, the name of the branch should be the ticket number (ex VIX-2100) and all commits should start with the JIRA issue number.
- They finish their work on it. If it has not been fixed or completed, leave a comment explaining what has happened with it, and put it back to Open. If work has finished on it, you next step is to create a PR request in GIT and the JIRA ticket transitions will occur automatically from there. The developer does not need to manually move the ticket to Ready to Merge.
- The maintainer reviews it. If it’s OK, they will merge it into master, and it will progress into Merged / Building in JIRA. If there’s some concerns about it, the maintainer comments in Github or in the issue itself. It then goes back to the developer to review, fix, etc. (go to step #3).
- Once it is merged, a development build will automatically be created and uploaded to the dev builds area of the website. Here it can be reviewed by other users or developers. The ticket will be closed with a field indicating the build number the resolution is contained in. If any issues are found, the ticket can be reopened, or a new bug filed that references the original ticket. If it is reopened go to step #3.
- The ticket stays Resolved for a while, until we do a public release. At this point, all Resolved tickets are used to build up release notes (to track what work as been done), they can be edited to include what version they have been fixed in, etc. Once the release is public, those tickets will be marked with the release build number.
Note that this process does not have any documentation steps integrated into it. If the work you do on a ticket involves updating the application documentation. i.e this site, then you should create a cooresponding issue in the Github issues for this site and document the needed changes. You can then make those changes or ensure they are documented so that someone else can.
Ticket Searches
There’s a number of searches we have made that can be handy:
All Open tickets by number
5 - Visual Studio
General Info
We use currently use Visual Studio 2019 or 2022 for development. You can use the community or free version that MS provides, or any of the higher paid versions. The current community version is quite good and is equivalent to the old Professional version. The vast majority of the code is in C#, with a small portion in C++. When you install Visual Studio, you will need the C++ build tools.
Settings
There are a couple settings that need to be configured in Visual Studio so your code formatting will adhere to our preferred style. We use tabs instead of spaces to format our files. The following screen shot shows how you should configure the editor to do this automatically. Most recently an editorconfig file has been added to the the project which should govern the code style in Visual Studio so this proactive step should not be necessary.
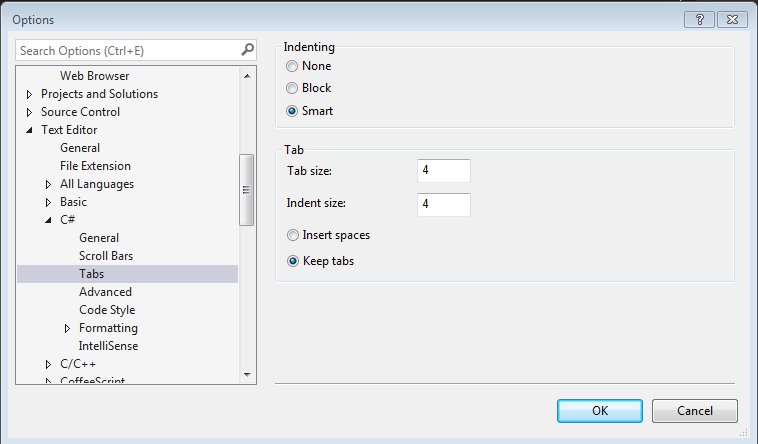
You should verify any changes you make are using the correct formatting. You can do this with any diff tool that shows white space in the files.
In the following diff, you can see that the new lines inserted have spaces instead of tabs for the indent formatting. This indicates that your settings are not correct and this should be fixed before continuing. If you are correcting any existing formatting issues, those should be done in separate commits specifically addressing format changes.
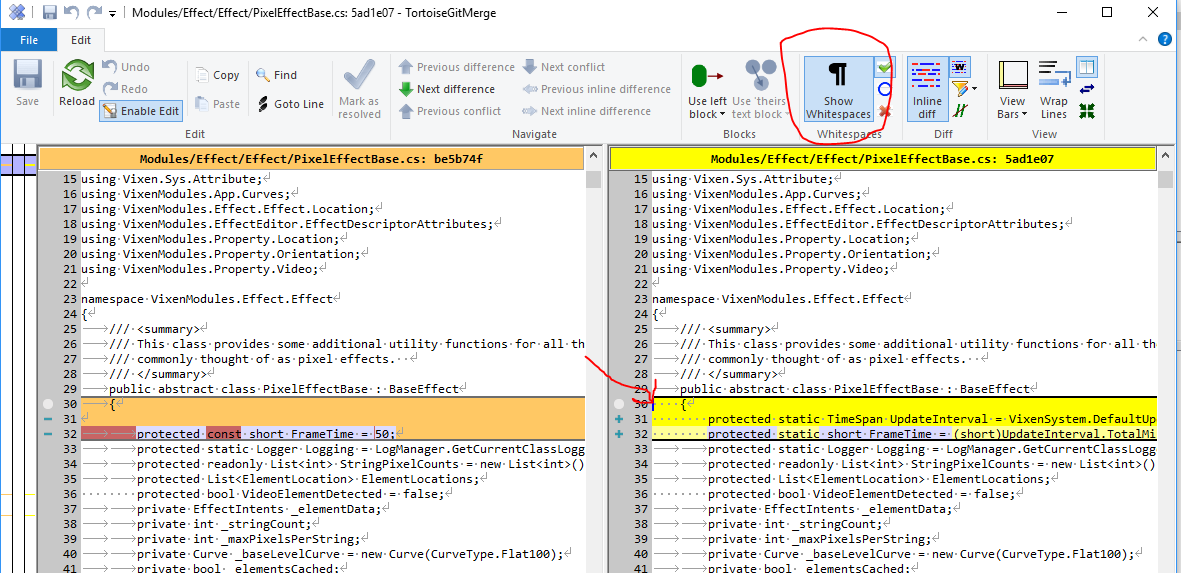
Extensions
The project uses WIX to build the installer for the application. If you are using Visual Studio, you should install the Heatwave for VS2022 extension so VS will recognize the project files. Heatwave
Building
Within Visual Studio, you can build / run the project in debug or release mode. The release mode provides for optimized builds, where the debug builds are more geared to debugging, especially when a debugger is attached. Another option is available for additional testing. Using msbuild at the command line, you can create a full installer that can be run just like the official releases. You can read more on how to do that here in the Vixen source project.
Installer
The Wix tool kit is used for creating the installer. There are two projects (Vixen.Installer and Vixen.DeployBundle) that handle packaging and building the installer. The Heatwave extension is necessary for Visual Studio to recognize the project types.
The Installer folder in the project tree has a README with information on the commands necessary to build the full installer. These same commands are used for production dev and release builds can can be run locally to produce equivelent output. See the Sanbox section below on deploying and testing those installs in a clean environment.
If you are running one of the pro versions of Windows, you can utilize the Windows Sandbox to test your builds in an isolated environment. This can be ver useful to simulate what a first time user might experience. See the Sandbox Testing in the Vixen source project for further information on how to do this.
Windows Sandbox
Windows Sandbox Configuration
We also have access to some very powerful tools courtesy of some of our partners who support open source projects. One very powerful tool is Resharper. If you are an active developer and are interested in using this tool contact us on the developer list and we can discuss getting you one of our team licenses. You have to be an active developer with a verifiable commit history.
7 - Execution Engine
Description of the execution process.
Most of this information is several years old, however most of the fundamental concepts are still valid.
Current System
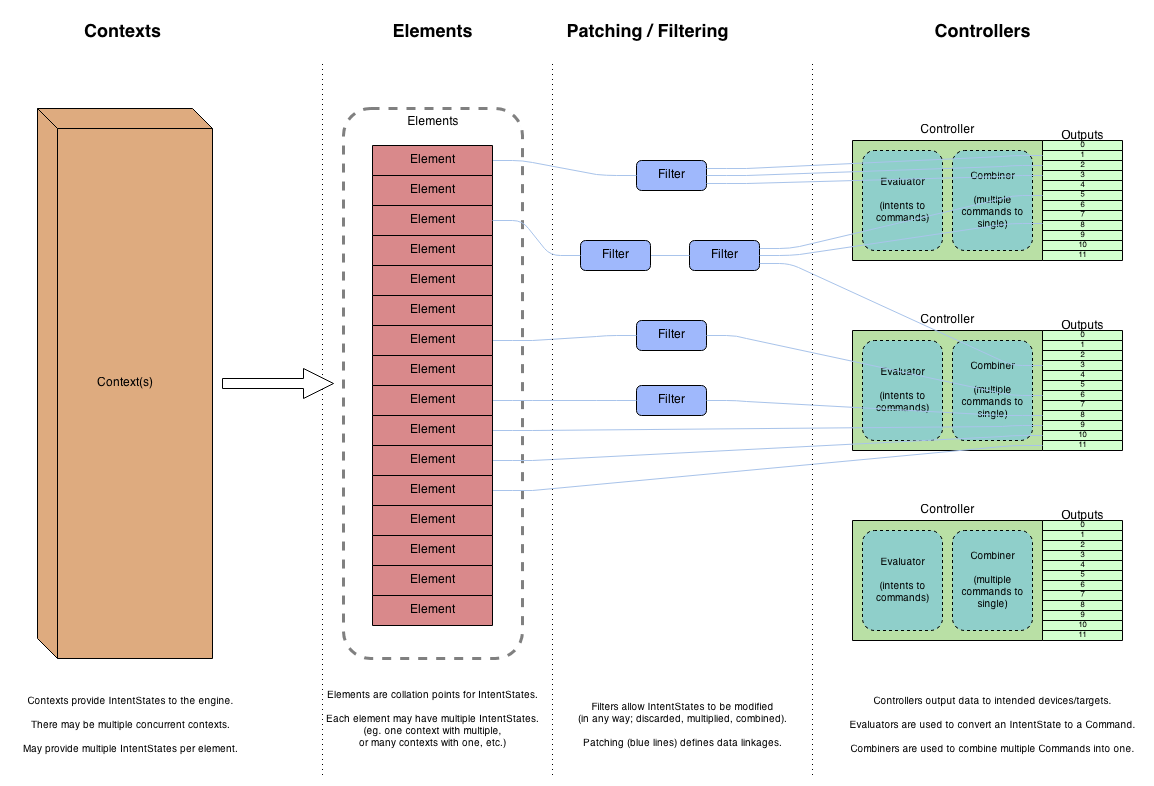
The goal of the execution engine is to take data from any number of currently running sources (Contexts), and end up with a single value for each output on each controller. It does this in a number of different stages.
The input data to the execution engine (from contexts) is an abstract data type (Intents), which represents the intended result for the element it targets. For example, it might specify to turn a light on to 50% brightness and color red. It does not specify any particular limitation or method on how that result should be implemented; that is the responsibility of the execution engine.
The end result of the execution engine is a data type called Commands. These are low-level data types which are in formats suitable for that specific controller. For example, it might be an 8-bit numeric value for one controller type, or a 16-bit numeric value for another.
In the diagram above, moving from left to right you can see the data flow process. The goal is to reduce many Intent data objects (on the left) to a single Command object (on the right), one per channel.
Contexts
The contexts are the sources of any data into the engine. Presently, there are two context types; a Sequence Context, and a Live Context. Both are currently used.
Sequence Context
A sequence context provides intents during execution of a sequence. Each effect is rendered to a collection of intents targeted on elements. During execution, the context provides these intents to the execution engine at the appropriate time (ie. while the effect is active).
Live Context
The live context is currently used for the effect preview in the sequencer and the web interface. The idea is to have a context that can be used for immediate execution of single effects. This could be used for testing/setup purposes, or for things like responsive displays (eg. triggering on user input, etc.)
Elements
The elements represent the abstracted items in the display. These would be things like Megatree strand, Minitree, etc. They should have no bearing whatsoever to the controllers and outputs used to implement a display. Because of this, elements utilize Intents to describe the activity currently taking place.
When the execution engine updates, it collects all intents for each element. Each element can contain zero or more current intents.
Patching & Filtering
To connect the intents on each element to the outputs on controllers, the data is patched. This connects the output of one block with the input of another. However, there is also some conversions that need to take place. There needs to be some intelligence or process that the user can utilize to describe how element intent data should end up as controller command data, as there may need to be some data conversion performed. These can be implemented as Filters.
Filters can be added in the data path between elements and controllers to help describe the process to take to accurately convert intended effects to real commands for controllers. For example, it is common for displays to implement multi-colored lighting elements with individual colors on each controller output (eg. an RGB item might use 3 channels: one for each color). To connect that RGB item to the appropriate channel, a Color Breakdown filter could be used. This would have one input (from the element), and be configured to have 3 outputs (one for each channel). The filter would process the incoming data, and split out the color portions of each lighting intent, into individual intents (one per color).
Additionally, to get from intent data on each element to the final command on each output, two things need to happen:
- The Intent data types need to be converted to a Command data type. This is called Evaluation.
- If there is multiple data objects destined for a single output, they need to be reduced to just one. This is called Combination.
For example, a lighting intent of turn on element to 50% brightness, color red might end up as a command on a red output channel with an 8-bit value of 128. The user can utilize filters to implement these steps if they want.
However, it is not strictly required: it is possible to patch elements directly to controller outputs (or through minimal filters that do not perform the two conversions). This is because each controller must provide a default or fallback way to perform these conversions.
Controllers
The controller framework takes the data processed by the rest of the system, and ultimately provides it to the specific controller module implementation, to actually output the data. However, there is also some extra things the controllers need to do.
A controller must specify a default Evaluator and Combiner that it wants to use to process the data, if it has input data which is not in the appropriate format. This allows a minimal set of patching; with sensible defaults, many controller modules can take data directly from elements, and convert them themselves.
Any input intent data is passed through the specified Evaluator. This will convert the data to a command. For example, the above mentioned lighting intent (brightness at 50%) might be converted to an 8-bit value of 128 for many controllers. (The color component of the intent could reasonably be ignored, as there is no way for the controller to make an informed decision as to what to do with it.) Note that this is a direct 1:1 correlation: no combining is performed at this step.
Once all intents have been converted to commands, the controller can combine them to a single command. (This is because channels need a single concise command value to output.) This Combiner should take multiple commands, and give a result of a single command.
A number of problems became apparent with the way this system operates during 2013, which required improvements/refinements to the operation of the engine.
Problems & Causes
Memory Usage
Users have reported extremely high memory usage when using V3 for their displays in 2013 in the order of multiple gigabytes. This is caused by a number of things:
- When pre-rendering effects, the effect renders and stores the intent data. Intents have a small amount of overhead. Normally this isn’t an issue, as intents were conceived to represent a range of raw values (ie. a single intent might represent 20 or 50 raw values in one object). Often, an intent can be smaller in memory than the equivalent raw values it renders to. However, when using Nutcracker effects, or when importing V2 sequences (with many tiny effects), a lot of redundant data objects (and overhead) are generated.
- When using the scheduler to run a show, the scheduler loads ALL sequences used into memory, and pre-renders them all. If using a lot of sequences, this can often blow out memory usage.
- Some of the data formats used waste memory. For example, using doubles to store color parameters instead of floats.
CPU Load
Users have also reported unreasonably high CPU load when running sequences. This is due to many factors, some small and some large. However, the primary one (relevant to this discussion) is the processing of intents in the execution engine, in real-time. That is, the:
- Instantaneous sampling of the current Intent objects in contexts to get IntentStates,
- Any filtering performed in the filtering and patching steps (eg. color breakdown filters, dimming filters),
- The evaluation of the IntentState object to get a specific Command, and
- Other miscellaneous overhead during the process (patching, object creation and disposal through the layers, etc.)
Scheduler Problems
Users have reported problems with the scheduler when executing shows. Some are caused by the memory usage (described above), however another common issue is that shows do not start on time (eg. 15 minutes after the scheduled start). This is caused by the operation of the scheduler: at the start time, it loads and renders all sequences that will be used. If there are complex sequences, or lots of them, this can take a significant amount of time, delaying the start of the show.
This problem, while valid, is not strictly related to the current topic of the execution engine. Some of the problem should be fixed within the scheduler operation (for example, loading sequences ahead of time, instead of doing preparation at the start of the show). However, the changes and solutions discussed below will significantly help fix this issue.
Proposed Solution
To solve the above problems, a number of changes can be made to the operation of the execution engine. The main problems above relate to CPU and memory usage. To solve these, we can doing the intensive work ahead of time (saving CPU load), and reduce the amount of data we actively hang on to in memory (reducing memory usage).
The following solution has come about as a combination of a lot of the ideas that dev group members have been discussing and suggesting over the last few months.
To explain the solution, first consider a more detailed view of how contexts operate:
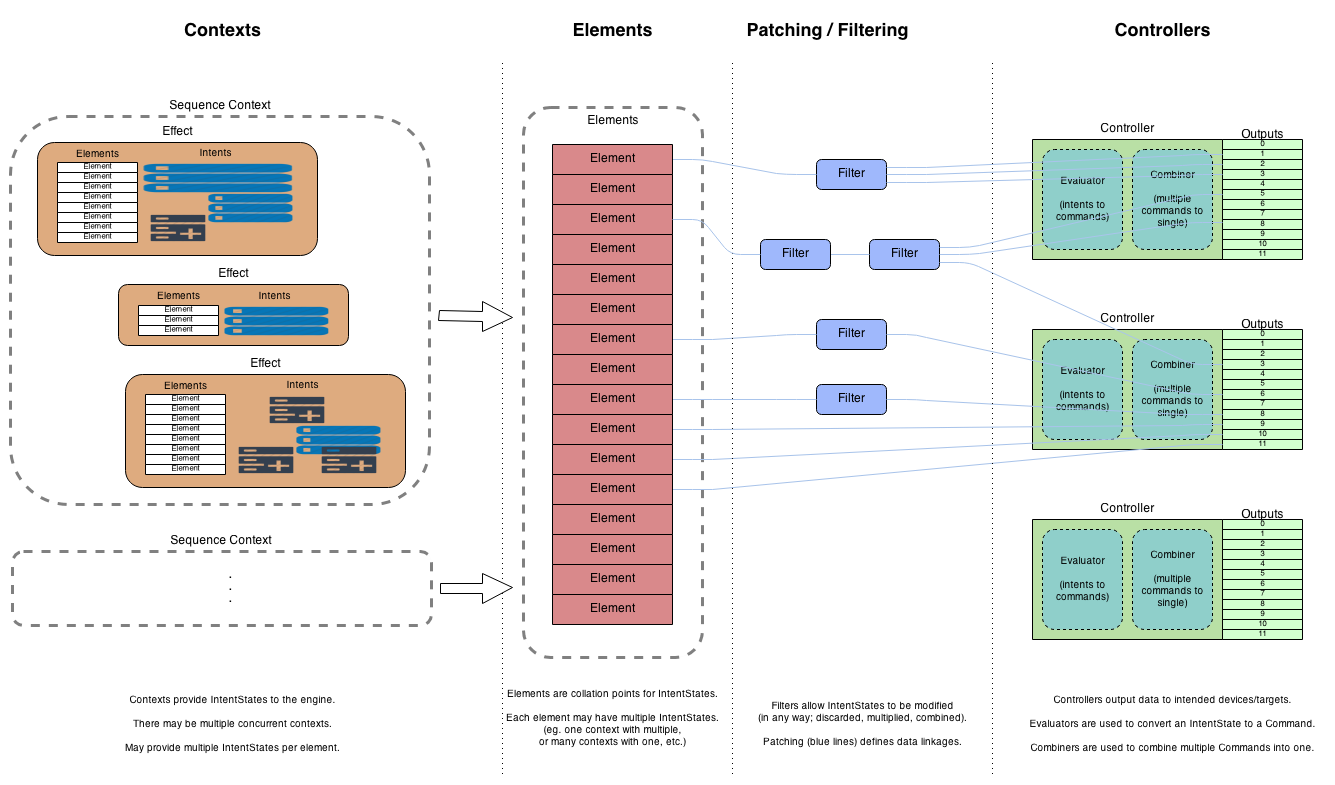
Note that there can be multiple contexts active at any time, even though the diagram only shows one main one. For example, we might have multiple sequences playing, or a sequence playing with some live data added, etc.
Currently, a sequence context contains effects, which all have been rendered against their target elements (usually ahead of time). These effects have collections of Intents to apply to elements at the appropriate time when the system is updated. When that happens, all current intents (at that point in time) are collated together at the element level, and then all processing from that point on is done in real-time.
The proposed solution involves adding the ability to perform this processing ahead of time, rather than in real-time. Currently, there is no way to do this: any intents that are given to the engine are for immediate execution. We would need to add interfaces/calls to be able to request the engine process a given set of intents for their elements, and return the data in a more processed form. This will give us the ability to perform a large chunk of that CPU intensive work ahead of time.
Conversely, we would need the ability to feed this data back to the engine somehow, at an appropriate point (ie. where the pre-processing stopped).
Given the flow of the engine, and where the intensive work sections lie, the most obvious candidate would be to render to and save the Command values that are used by the controllers. The operation of the controllers also lends a suitable point to insert this data at a later point: at the command combination stage.
Thus, with pre-processed data, the data flow would look like this:
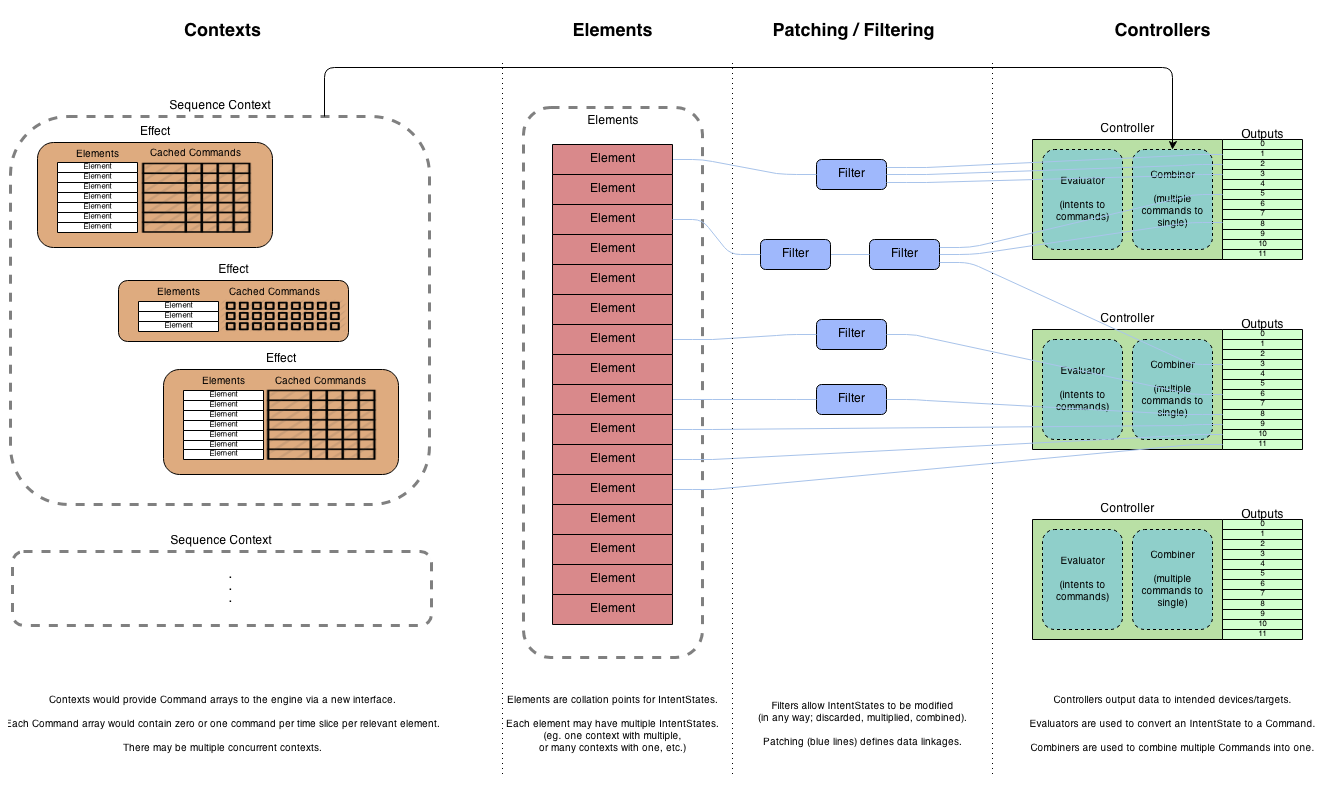
The line at the top indicates the contexts providing rendered Command data directly to the controllers via a new interface.
Other Solution Notes
These are some other miscellaneous notes/considerations about how it would work or be implemented.
The pre-rendering results/data that the engine provides would be an array of Command values. As there is no timing information inherent in these values, the wrapper data structure would also contain the information needed — eg. if the data is in 25ms chunks, 50ms, etc. This information will be needed by whatever is retrieving the data; ie. to index into the array accurately to get the correct Command value.
Intents: not needed anymore
In the old process, effects had to store their generated Intent values, as they were the data that was used to give to the engine. In the new process, they would still be needed (to provide to the engine to pre-process and generate cached data), but only as transient data: they would be able to be disposed of afterwards. This can be of great benefit for some cases where we have many small effects with many small intents: we would only be keeping the data that is needed and used at the end.
If we were to discard intents after their brief existence, we need to consider if we need them around for anything else. Currently, they are also used for two other things that I know of: generating the bitmap of the effect in the sequencer, and when providing data to the preview modules at runtime. This needs more thought, to ensure we can work around both of these, but a quick consideration makes it seem possible:
- The bitmap can still be generated from the intents if that’s the best option: we would need to make sure that it is generated during the transient time that we have the intent data. After that, the bitmap can be cached.
- The preview module type integration into the system has never been ideal. It may be worth reconsidering how they get data in the process, and where they lie. (If we implement smart controllers, maybe they would be more suitable there? Or, maybe we can come up with a different cache format for the previews that would be suitable for them.)
Are there any other places that we use intent data that anyone can think of?
Tracking Changes
If we cache data for later execution by pre-processing information against a specific configuration, we need to make sure we know if that configuration changes (or the source information). As such, we need to be able to know if/when we should discard the pre-processed data.
I thought there was a ticket covering this work, but I can’t find it. Essentially, I had plans to add a new extension that could be applied to objects that give them the ability to track their state instances, by keeping a random ID. This ID would be changed every time the object changes in any sort of significant way. Other items that use the object would track that ID, and if if’s not the same as the current one, they know that their data is out-of-date.
For example, the system config could have an instance ID, which changes every time the configuration is changed. The effect caches would be rendered against a specific instance of the configuration, and track that instance ID. They would also track the instance ID of the effect that they are caching. At any point they are able to detect if the effect or display configuration changes, and if so, we know the cache is invalid and needs to be regenerated.
Memory vs. Disk Storage
This solution should hopefully reduce the amount of memory used, as it eliminates the need to keep Intent and IntentState objects, and only saves the raw data being used by controllers. We can save the amount of active memory used even further, though, by saving some of it to disk as needed.
In some cases, eg. working in a sequence in the editor, we would likely want more cached data available, so can keep it in memory. In other cases, running a show through the scheduler we wouldn’t want to keep ALL cached data in memory for all sequences. When not playing a particular sequence, we could save the cache for its effects to disk, and read it in later as needed.
There’s more detail we could go into here, but that’s a general idea.
TODO: disk cache could be generalized a bit, and also used for bitmap image caching
Persistence of data between software sessions
TODO: saving all cache to disk to persist
Maintaining real-time intent execution
What do we lose?
TODO: (only really the ability to dynamically process intent states in the filtering stage. However, our current filters are static, and we don’t [yet] have any filters that are dynamic in this step.)_
Solution Assessment
So, how does all this solve the initial problems?
CPU Load Concerns
It should be fairly straightforward how this addresses CPU load: the most intensive parts when rendering it real-time are all the parts in the middle of the diagram. (interpolating intent states, processing through filters, evaluating IntentStates, etc.). Not having to do this work means we save a lot of CPU time.
What CPU use do we still have? well, looking at the diagram, the following areas present themselves:
- Contexts: there would still be multiple effects in the sequence, each with their own cache of pre-processed data. There is still some CPU involved in iterating through effects, and tracking which ones are current or not. This should be fairly negligible; most sequences have a reasonable number of effects (100’s, maybe 1,000?), and these are already sorted by time order. Iterating through them in order over the course of a sequence is trivial.
- Data injection setup: as the effects with pre-cached data run, they would still need to attach to their respective controllers and/or channels to provide data. This needs a bit more careful thought, and care taken during implementation, especially with large channel counts. It should be possible to attach per controller, which would avoid too much CPU overhead.
- Data retrieval: as long as the cached data is stored in a way that allows for easy, linear iteration, ie. an array,there should be very little overhead needed to pull values out of the cache.
- Command combination: The final step is combining multiple commands. This should still be fairly easy to do, for two reasons: the actual algorithms are fairly simple to combine data, and there’s often not too much data to combine. That is, I would estimate that most of the time, there is only a single effect or intent playing for a given channel.
Memory Concerns
There are a number of ways that memory usage should be mitigated:
- Storing raw command data instead of their source intent values. This avoids a lot of transient IntentState and Intent objects. [side note: technically, it would be possible in some circumstances to *increase* memory usage, as we could be storing lots of redundant or linear command values, instead of a single intent the accurately describes it. However, the practical usage means this shouldn’t really be a problem.)
- Any cached data that is unneeded (eg. scheduler show sequences that aren’t currently playing) can be stored on disk only, and flushed from memory. This means we only hang on to what we REALLY need.
Scheduler Concerns
The scheduler problems mentioned above would mostly be mitigated by this solution: data would be cached and ready to go (persisted on disk), so the scheduler can open and start playing sequences with very little delay.
It’s also worth noting that some extra work should be done on the scheduler regardless: improvements to make it a bit smarter about getting data ready ahead of time (eg. in case a sequence HASN’T been pre-processed and cached, or if it’s dirty from a display setup change, etc.).
Alternatives
There’s a few other options for various components that have been suggested or are possible. This section attempts to look at them and address how they are different to the proposed solution above.
TODO: expand on all of these
- caching an entire sequence vs. just effects (size of null data, flexibility in use and sequencer, regenerating for any change)
- inserting data AFTER the combination: ie. locking controllers to just cached data (loses a lot of flexibility and power of V3)
- storing the whole cache on disk, and streaming from there (loses flexibility)